英伟达推出新AI模型Fugatto,可修改并生成新声音
英伟达(NVDA.US)推出了一款用于生成音乐和音频的新型人工智能(AI)模型,旨在为制作音乐、电影和视频游戏的人们提供服务。
根据英伟达的说法,这款模型名为Fugatto(Foundational Generative Audio Transformer Opus),可以使用任何文本和音频文件来生成或修改音乐和声音。

例如,该模型可以根据文本提示创建音乐片段,从现有歌曲中删除或添加乐器,改变声音中的口音或情绪,甚至发出从未听过的声音。
英伟达应用音频研究经理、管弦乐队指挥兼作曲家Rafael Valle表示:“我们希望创建一个能像人类一样理解和产生声音的模型。”
英伟达指出,广告代理商可以使用Fugatto快速定位多个地区的现有广告,并在配音中加入不同的口音和情感。此外,视频游戏开发者可以使用人工智能模型修改游戏中预先录制的资产,以适应用户在玩游戏时不断变化的动作。
Fugatto可以使小号发出狗吠声或萨克斯管发出喵喵声。该公司补充说,通过微调和少量的歌唱数据,研究人员发现它可以处理未经预先训练的任务,比如从文本中生成高质量的歌声。
英伟达表示,Fugatto的完整版本使用了25亿个参数,并在包含32个Nvidia H100 Tensor Core GPU的Nvidia DGX系统上进行了训练。该模型的整体工作耗时一年多。
Fugatto可能会与Runway等初创公司以及 Meta Platforms(META.US)等大公司的类似技术展开竞争。10月,Meta 发布了名为Movie Gen的人工智能模型,该模型可以根据用户提示创建逼真的视频和音频剪辑。
今年 2 月,ChatGPT制造商OpenAI推出了Sora,它可以根据文本指令创建逼真且富有想象力的场景。这家由微软(MSFT.US)支持的公司尚未向公众发布文本转视频模型。
相关文章

直击WAIC | 对话齐向东:未来程序员不需要那么多,但网络安全会是热门专业
7月6日下午消息,2024世界人工智能大会(WAIC 2024)期间,新浪科技独家对话全国政协委员、全国工商联副主席、奇安信集团董事长齐向东,他认为,随着AI技术不断发展...

中证A500指数基金总规模已逼近2000亿份!多只基金刚成立不久却转型了?
今日,华夏基金公告称,自2024年11月18日起,“华夏中证A500指数”转型为“华夏中证A500ETF联接”;广发基金也公告称,将“广发中证A...

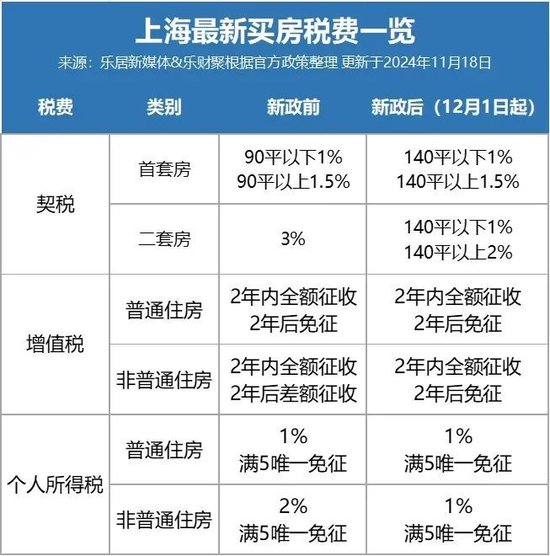
“现在主要是劝房东降价” 昨天上海房产交易中心人挤人
昨天(12月1日),是上海二手房交易税费新政执行的第一天,又恰逢周末,上海各区房产交易中心的人流明显增多,甚至出现人挤人的情况。...
张军扩:房地产市场止跌回稳仍需时日
专题:2024三亚·财经国际论坛...

内房股普升 雅居乐集团(03383)涨近2% 机构指房地产行业数据有望随政策出台企稳
内房股普升,雅居乐集团(03383)涨1.92%,绿城中国(03900)涨1.63%,中国金茂(00817)涨1.61%,旭辉控股(00884)涨1.52%,华润置地(01109)...